I’ve done a lot of computational experiments in my days and have slowly and diligently ascended a slope of experimental mismanagement. Every project starts with an empty directory and attempts to build towards a paper, report, or presentation. Here are my thoughts on the right way to do it.
Decide on a process up front and follow it
When you start a project it is always just a few files, just a few scripts, and just a few collaborators. Now is the most critical moment in organizing your project. When you get started you must have the discipline to follow a process that seems silly with just one other collaborator.
Choose your tools and choose them wisely. Always start your version control, data management plan and automation at the beginning. If you don’t have time to do these things when the project is small and the deadline is far away, then you won’t have time to do it when the project is sprawling and the crisis is upon you.
Control versions of the code and data
A version control scheme is critical to handling collaboration. Once you have two people working on a project, there will be divergence in files. Git and Github has become the de facto standard for version control. Remember that without version control, you will end up emailing files around and never be confident that everyone working on the project has the latest fixes to the code.
Git is the *de facto* standard for version control. Image Credit: Git-scm.com
Git is sufficiently flexible to give you lots of ways to have bad workflows. Start with the obvious, a master branch that always works. Topic branches that implement changes. When a collaborator has changes to contribute, they should open an issue to propose the changes, create a branch, commit to the branch, push it to the repo (or their fork for public projects), and make a pull request. The issue-pr-review-merge cycle is great for ensuring quality in your project. Every pair of eyes that looks at a line of code before it gets merged is another chance to catch a bug before it derails your project.
This is a case where Computational Science projects differ from pure software engineering projects. When the goal of the project is working software, you can define tests to ensure that the code is working and make sure that any code that is merged does break the regression tests. These tests allow you to feel confident that the code is working. In the scientific project workflow, you are not writing software to work, but instead to produce a paper. The worst thing that can happen when preparing a paper is to find a bug the night before the submission deadline that invalidates all your results. These bugs can be subtle and you never have enough testing to catch every bug before you see it. Software Engineering has the benefit of users who will report bugs to the developers. In a science project, the researchers are the only people with the opportunity to catch the bugs they write.
Separate input data from results data
When thinking about version control you have granularity and storage requirements at odds with each other. If you want to create a version for every single change you are going to take up a lot of space. For the code this is not too much of a problem and you can go as granular as you want with versions. But for data files, you can quickly get into situations where small changes to the data creates large binary diffs in the version control software. Thus it is important to store important versions of the data without losing too much history.
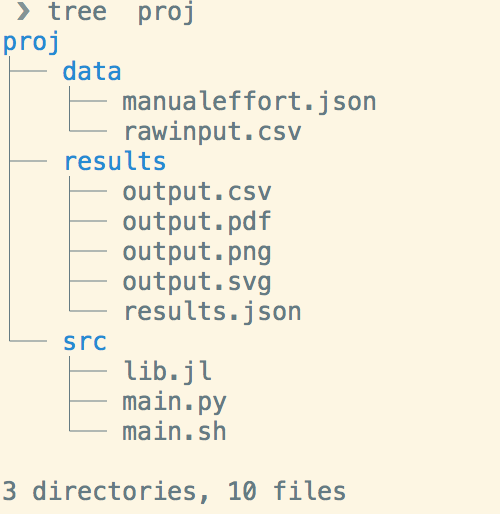
Project layout is very important. Separating manually created data from automatically generated results is important.
How can you determine the important versions of the data? My strategy is as follows:
- If I edited a file by hand then it is important.
- If this file was collected/generated automatically, but cannot be reproduced at a later time. For example web scraping data cannot be collected later because the websites will be different.
- If this data can be reproduced exactly based on a snapshot of the code, and I have that version, it is not important.
I used to use a single data directory for each project where all input data and results would live. After all, what is a result, except input data to the next script. This leads to confusion about what files are important to track and which are not. An easy rule to determine if you should check a file into the repo is: “Can I check out a version of the repo and reproduce this file quickly and exactly?” If the answer is yes, then don’t store it in the repo and feel free to delete it.
Now a lot of times you feel like a file should be reproducible, but don’t have enough confidence to
remove that file permanently. Instead of committing each version of the results you should store
them outside the repo but in a directory results/VERSION/path/to/file, where VERSION is a git
commit hash. If you think a data file is worth saving at all, then you must save the version of the
code that produced that data file. Eventually you will want to use a figure, or table in a
presentation, and will need to verify exactly how that figure was made. A result you can’t
reproduce is no result at all.
Automation accelerates innovation by reducing effort
It may seem obvious but most data scientists and computational scientists are not utilizing software engineering automation best practices. The goal of software engineering automation is to reduce effort and mistakes so that you can focus on improving your code with confidence.
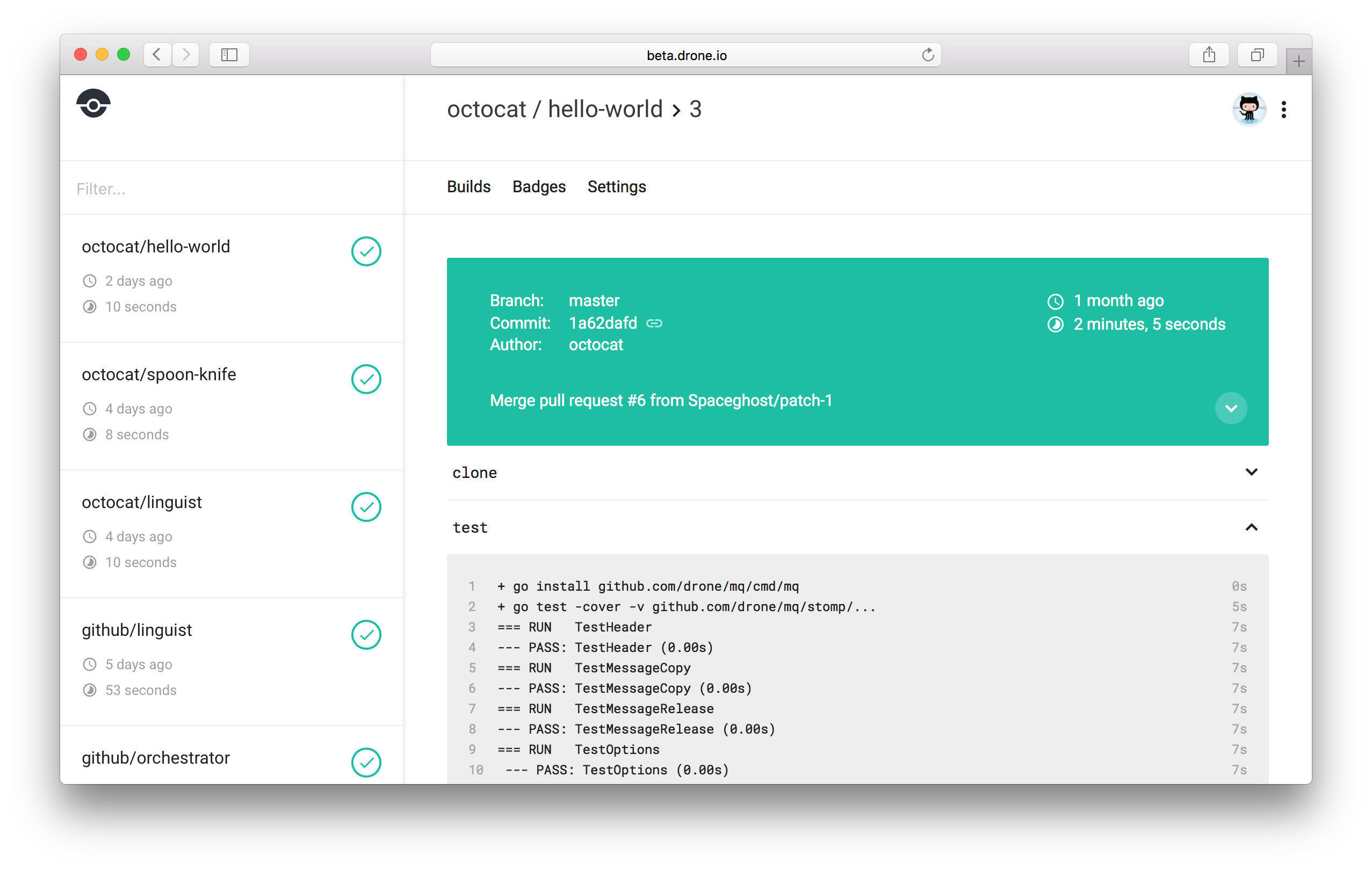
Continuous Integration is the gold standard of software automation. Image Credit: Drone.io.
It all starts with testing. You need to be able to certify that the software works at any given time. The critical step here is to define “works” in a rigorous way. Software tests ensure that the code does what you say it does. Whether that means, it has the features, its analysis results are correct, or is free of defects, you need to put down a contract in writing. And that means software testing.
You can debate the merits of Test Driven Development (TDD), Unit vs Integration tests, and software testing frameworks until the end of days, but the critical step for any project is to define a testing goal and hit that goal.
When I am brought on to a project with no testing infrastructure, I start with integration tests and then work towards unit testing. If you don’t have a formal testing process, then every developer has an ad hoc check to make sure the software works. These checks are the basis of the integration tests. You start there and then work toward 100% test coverage of the public API of the project.
As your codebase becomes more mature, the testing should focus on ensuring that promised functionality works and reported bugs, don’t recur. Whatever your testing methodology, you should feel comfortable saying “tests pass, ship it.”

Shiping Ships with Confidence. Image Credit: Giphy.com
Once you have testing in place, work on using a continuous integration platform to manage everything about your project. Travis-ci.com is good for software projects, but doesn’t integrate with your local infrastructure such as an institutional HPC cluster. For that you can run drone where you can run CI with access to your local databases and hpc clusters inside your institutional network. Drone takes a while to set up and but the downstream payoff is worth it.
Conclusions
These are some hard won lessons that I have learned in my time as a researcher. I wish that graduate school training provided more instruction in project and data management, but this is cost of putting our most important scientific endeavors in the hands of a labor base with 100% turnover every 4-7 years. We are all figuring everything out as we go along.
- Version control your source code
- Separate hard to collect data from easy to generate results
- Automate everything you can
Hopefully this information will help you organize your next project better. Always keep improving!