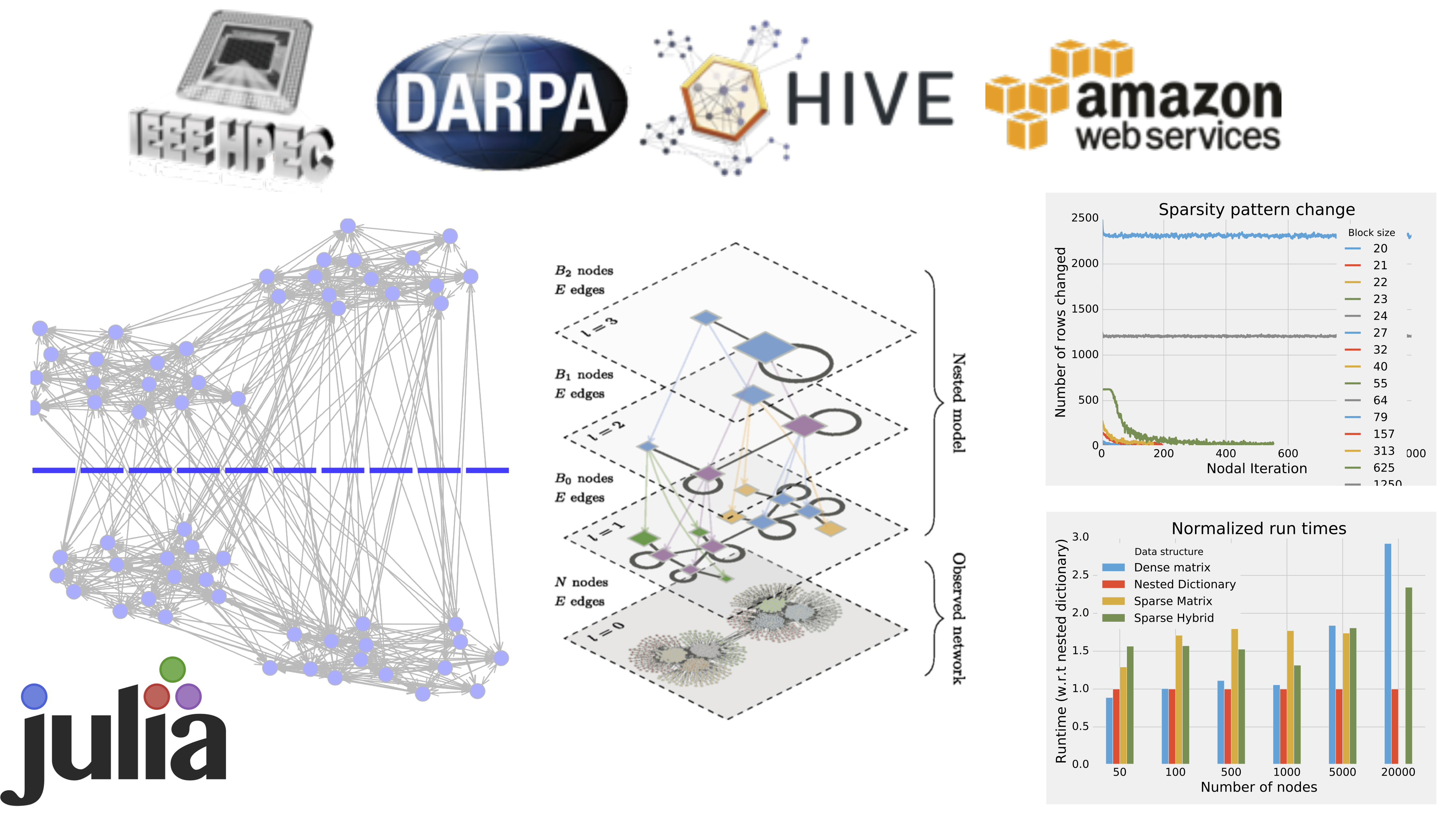
Community detection in graphs is important to the study of social networks, power grids, and complex biological networks. Graphs can be stored in computer memory in diverse representations with differing performance characteristics. Community detection algorithms create a dynamic graph as an internal data structure for tracking agglomerative merges. This community (block) graph is modified heavily through operations derived from moving vertices between candidate communities. We study the problem of choosing the optimal graph representation for this data structure and analyze the performance implications theoretically and empirically. These costs are analyzed in the context of Peixoto's Markov Chain Monte Carlo algorithm for stochastic block model inference, but apply to agglomerative hierarchical community detection algorithms more broadly. This cost model allows for evaluating data structures for implementing this algorithm and we identify inherent properties of the algorithm that exclude certain optimizations.